论文题目:RANGER21: A SYNERGISTIC DEEP LEARNING OPTIMIZER
论文链接:https://arxiv.org/pdf/2106.13731.pdf
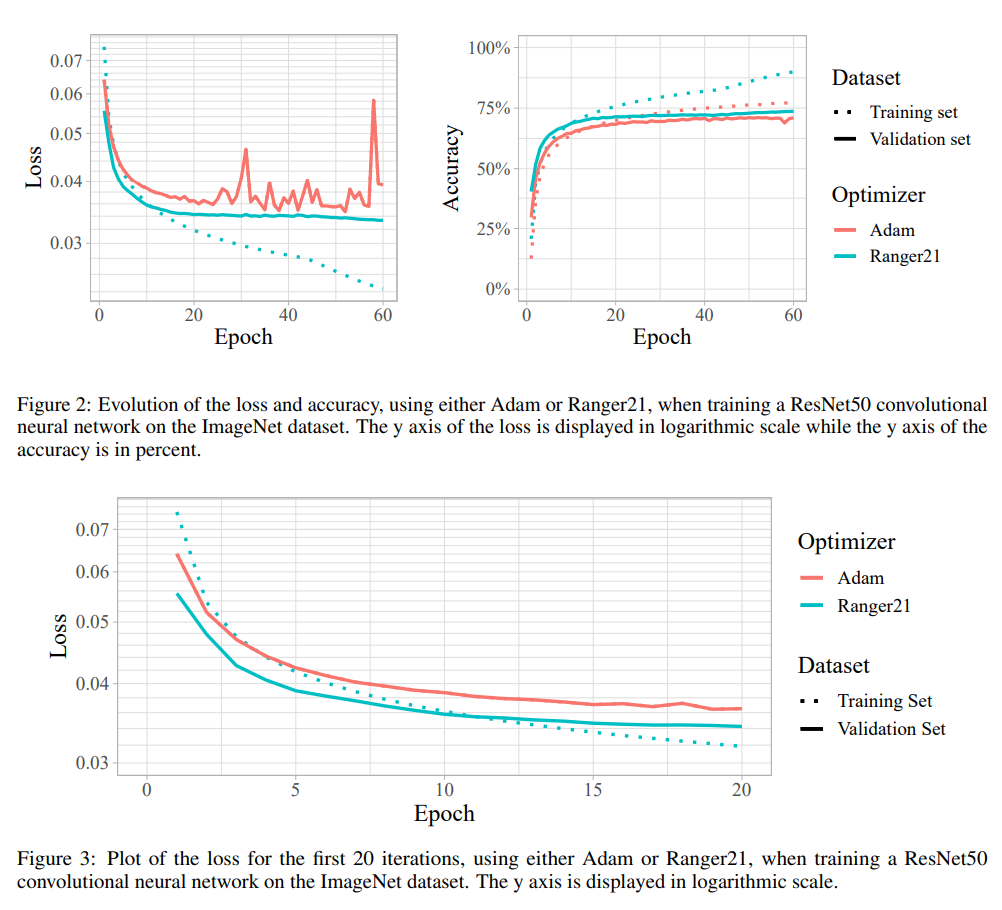
由于对神经网络的性能至关重要,因此每年都会发表大量关于该主题的创新论文。 然而,虽然这些发表论文中的大多数都提供了对现有优化算法的增量改进,它们倾向于作为新的优化器而不是可组合算法呈现。 因此,许多有价值的改进在最初的论文中很少见。 利用这一未开发的潜力(之前论文都没有对现有优化器进行组合),这篇论文引入了 Ranger21,这是一种新的优化器,它结合了 AdamW 和八个组件,这些组件由作者在审查和测试论文思想和效果后后精心挑选的。论文实验发现发现由此产生的优化器显着提高了验证准确性和训练速度、更平滑的训练曲线,甚至能够在没有批量归一化层的情况下在 ImageNet2012 上训练 ResNet50,解决 AdamW 系统地停留在糟糕的初始状态的问题。
Ranger 21深度学习优化器整合了以下优化思想,尤其是:
- 使用 AdamW 优化器作为其核心(或者,可选的 MadGrad)
- Adaptive gradient clipping:自适应梯度裁剪
- Gradient centralization:梯度中心化
- Positive-Negative momentum:正负动量
- Norm loss:权重软正则化
- Stable weight decay:稳定权重衰减
- Linear learning rate warm-up:线性学习率预热
- Explore-exploit learning rate schedule:搜索性的学习率规划器
- Lookahead
- Softplus transformation:激活函数
- Gradient Normalization:梯度归一化
2.1 AdamW (adaptive moment estimation):核心优化器
由于 Adam(W) 是最常用的优化器之一,许多发表论文提供了各种增量以及对改算法的创新改进,因为这些单独的改进 通常是可组合的,这也是作者选其作为核心基础的原因。

AdamW通常会给模型带来更低的训练loss和测试误差。除此之外,在固定相同的训练loss的情况下,AdamW也有更好的泛化性能。具体对比解释可以参考该笔记;https://zhuanlan.zhihu.com/p/329877052
2.2 Adaptive Gradient Clipping:自适应梯度裁剪
由于过多梯度的反向传播,小批量零星的“高损失”可能会破坏随机梯度下降的稳定性。 这是较小批量和较高学习率的常见问题。 为了解决这个问题,可以使用梯度裁剪,确保梯度保持在给定阈值以下:
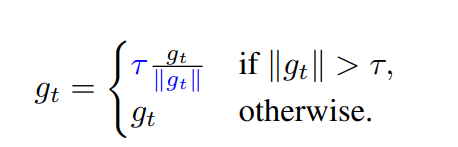
理论研究表明,梯度裁剪有助于优化器平缓过渡损失的非平滑区域并加速收敛。 但是,原始梯度裁剪会影响训练的稳定性,并且找到一个好的阈值需要根据模型深度、批量大小和学习率进行精心调整。
Ranger21使用自适应梯度裁剪来克服这些缺点。 在自适应梯度裁剪中,裁剪阈值会动态更新,保证梯度范数与参数范数的单位比率成正比。公式如下:
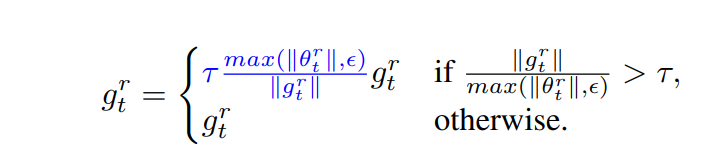
?
\epsilon
?是一个常数,默认值为
1
0
?
3
10^{-3}
10?3,避免冻结零的初始化参数,
τ
τ
τ默认情况下为 10?2 并且 r 表示我们正在处理层的某个维度参数而不是整个层的参数。
2.3 Gradient Centralization
高性能网络优化算法梯度中心化(GC, gradient centralization),能够加速网络训练,提高泛化能力以及兼容模型fine-tune。
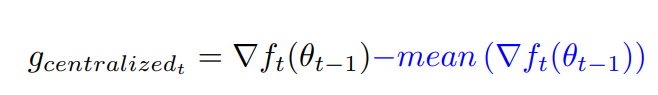
梯度中心化对损失函数施加了约束,并充当正则化器,据作者说,该算法使训练更加平滑。 在实验中,当在包含全连接层和/或卷积层的网络上使用它时,我们观察到改进的泛化、更平滑的训练曲线和更快的收敛。
2.4 Positive-Negative Momentum:正负动量
Momentum 用于现代深度学习优化器,既可以消除训练噪声,又可以降低优化器卡在损失图的鞍点和梯度消失部分的风险。 Positive-Negative Momentum 算法如下:

正负动量的关键思想是保留两组一阶矩估计,一组用于奇数迭代,一组用于偶数迭代。 优化过程中应用的矩是两组的平均值,一个为当前动量估计分配正权重,一个为前一个动量估计分配负步长。根据 原论文,这模拟了将参数相关的各向异性噪声添加到梯度中,有助于逃避鞍点并将优化器推向更平坦的最小值,理论上可以产生更好的泛化。
在本篇论文的测试中,作者能够通过实验验证正负动量确实可以提高各种数据集的性能,并以互补的方式与 Ranger21 中使用的其他算法进行集成。
2.5 Norm loss:权重软正则化
在 AdamW 风格的优化器中,权重衰减按照下面公式计算(其中 η 是学习率,λ 是缩放权重衰减的参数,θ 是我们正在优化的参数)并在更新步骤期间从参数中减去
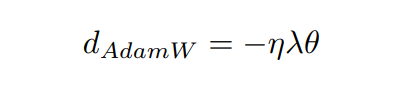
Norm Loss来自今ICPR 2020论文Preprint: Norm Loss: An efficient yet effective regularization method for deep neural networks,核心公式如下。给定权重矩阵
∥
∣
c
o
∥
∣
\||c_{o}\||
∥∣co?∥∣,它考虑了权重矩阵的欧几里德范数,使得权重矩阵被推向一个单位范数,这与传统的权重衰减不同,传统的权重衰减一直将权重推向零。
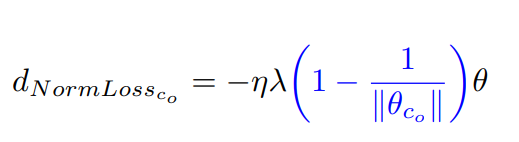
2.6 Stable Weight Decay
AdamW 风格的权重衰减使用优化器的学习率来对衰减进行加权。然而,实际步长不仅是学习率的函数,也是 v ^ t \hat{v}_{t} v^t? 的函数,它代表了梯度大小。 因此,实际步长在迭代过程中发生变化,并且当 v^?t 下降到零时,为训练的第一次迭代校准的权重衰减对于以后的迭代来说太大了。
为了解决这个问题,ICLR 2021 公开论文:Stable Weight Decay Regularization提出了 Stable Weight Decay。
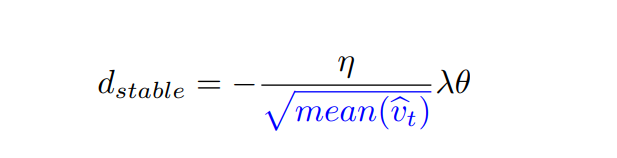
在论文的测试中,作者发现稳定权重衰减为我们在视觉任务上提供了显着的泛化改进,即稳定权重衰减允许自适应优化器在视觉任务上匹配并超过 SGD 效果。此外,论文观察到它可以与 Norm Loss 无缝集成,并且这两种方法的好处是相加的,因为它们从不同的角度处理权重正则化。
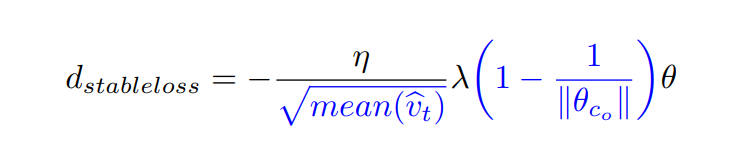
###2.6 Linear learning rate warm-up
最初的 Ranger 优化器基于 Rectified Adam 优化器 ,该优化器试图修复 Adam 在第一次迭代中由于大量更新而遇到的一些不稳定问题。 本篇论文引入了一个更简单的替代方案,仅依赖于学习率的预热,β2是第二动量参数,由于此规划器可以产生对于较短的训练迭代次数来说太大的预热,我们另外将其重置为第一次
t
w
a
r
m
u
p
t_{warmup}
twarmup?热身迭代
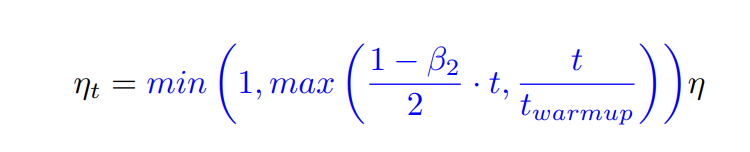
在论文测试中,我们发现这种预热策略与 Rectified Adam 相似,避免了第一阶段的步长过大
迭代,同时实现起来要简单得多。
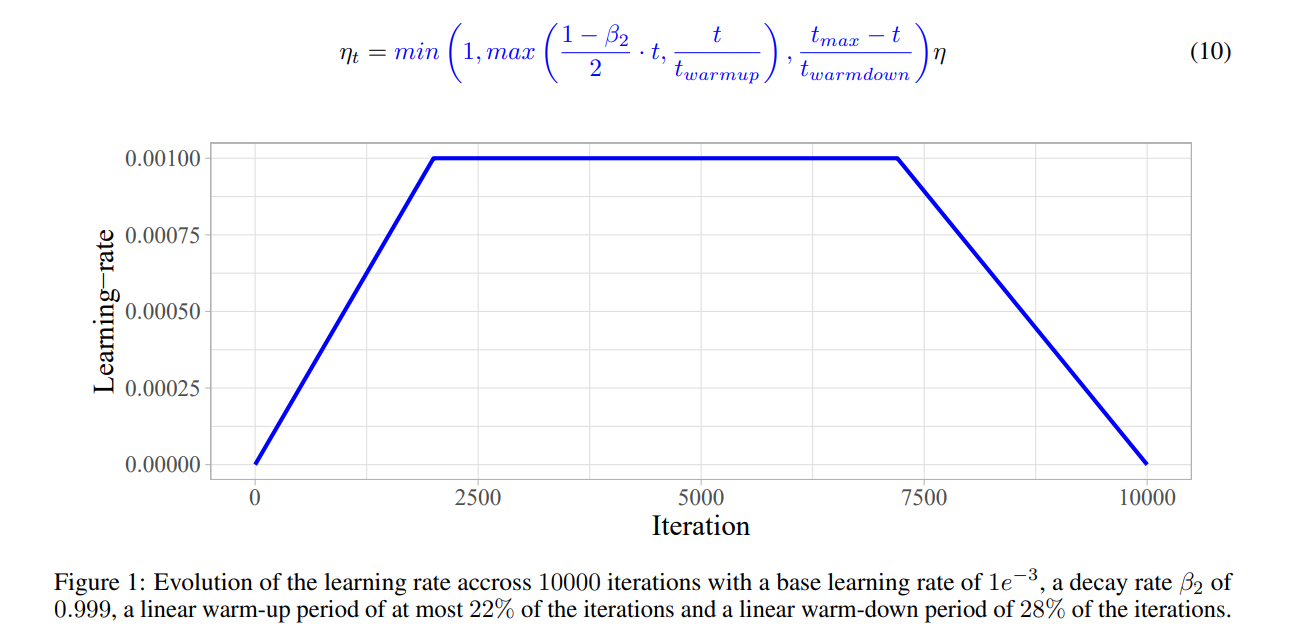
2.8 Explore-Exploit learning rate schedule
Wide-minima Density Hypothesis and the Explore-Exploit Learning Rate Schedule:论文指出宽最小值比窄最小值更好地泛化。 在本文中,通过详细的实验,不仅证实了宽极小值的泛化特性,我们还为宽极小值的密度可能低于窄极小值的密度的新假设提供了经验证据。 此外,在这一假设的推动下设计了一个新颖的探索-利用学习率计划。 在各种图像和自然语言数据集上,与其原始手动调整的学习率基线相比,同时表明我们的探索-利用计划可以使用原始训练预算将绝对准确度提高 0.84% 或高达 57% 减少训练时间,同时达到原始论文的准确性。
2.9 Lookahead
Lookahead2,一种由保持权重的指数移动平均值组成的技术,每 k 步(默认为 5)更新并替换为当前权重。 为了实现 Lookahead,可以在通常的优化步骤结束时应用算法 3(其中 βlookahead 是移动平均线的动量,默认为 0.5)。
3 Ranger21
Ranger21 是上述所有组件的组合:

由于集成了各种算法于一体,官方实现代码篇幅还是很长的,大家可以直接打开链接查看;
4 实验结果与总结
许多论文对现有优化器进行了增量改进,将它们呈现为新的优化器,而不是可以组合的模块。 本篇论文为了充分利用正在进行的深度学习优化研究,意识到这种模块化很重要,所以设计 Ranger21 是为了突出从这种组合中获得的好处:测试并将多个独立的改进组合成一个明显优于其单个部分的单一优化器。
通过结合许多子领域(例如动量、损失和重量衰减)的改进,论文发现 Ranger21 能够训练其他优化器根本无法训练的模型,例如 Normalizer-Free Resnet50。 更重要的是,对于给定的模型,Ranger21 通常能够在不影响泛化的情况下加速学习并实现更高的验证精度