

对游戏进行优化,首先要确定性能瓶颈,然后对性能瓶颈进行优化,以改善我们游戏的性能。
下面分四步进行详细分析:
- 一. 确定性能瓶颈
- 二. CPU优化
- 三. GPU优化
- 四. 内存优化
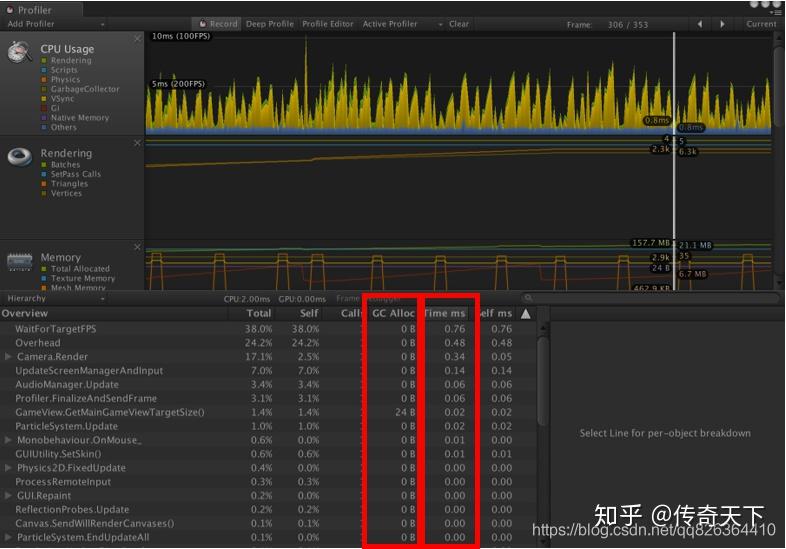
Unity Profiler中最常检查的内容是CPU Usage,其中GC Alloc和Time ms最为重要。GC Alloc展示了每帧在Mono堆上进行内存分配的代码,过于频繁的在堆上分配内存会导致Mono定期触发GC.Collect操作,进而导致游戏卡顿。因此我们建议对单帧2K以上的内存分配,以及每帧20B以上的内存分配进行排查。如果能把堆内存的分配降到最低是最好的。Time ms展示了每一帧CPU耗时最高的函数,通过这项可以找到耗时不合理的代码,然后进一步对代码进行优化。
当发现某个Update函数特别耗时时,没有有效的手段。进一步定位问题出自该Update函数的哪一个模块或哪一段代码。
推荐使用Unity Profiler提供的性能采样接口,来更精确地分析定位客户端存在的性能问题。设置自定义采样,然后在Profiler窗口就可以看到采样的函数性能消耗,从而确定是哪一个函数消耗最大。
鹅厂程序小哥:Unity3D-使用Profiler精确定位性能热点的优化技巧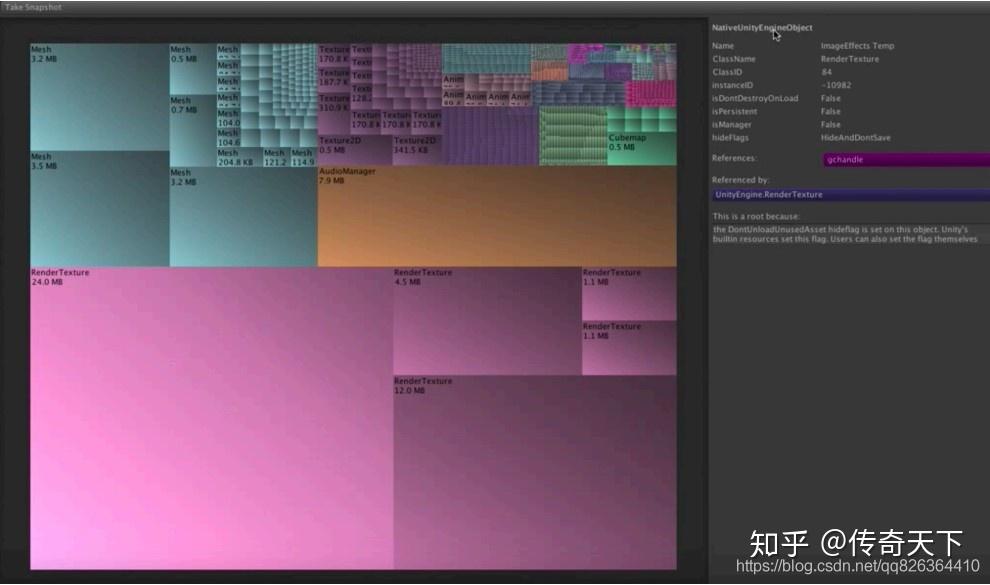
Unity为5.3以上的版本提供了一个新的Memory Profiler工具。这个工具通过图形的方式展示了工程中占用内存最高的资源类型,因此可以很方便的进行资源内存的优化。另外还可以在游戏的不同时间点抓取多个快照,通过比较内存占用的不同,来发现某些资源内存泄漏的情况。
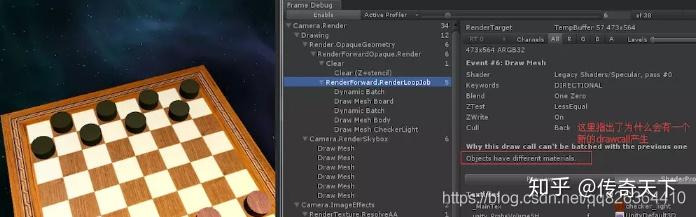
通过Enable按钮可以抓取当前渲染帧的全部数据。 了解不能合批的原因,DrawCall过多的原因。例如,同一张图集,为什么会多一个DrawCall,因为对象的材质不同。
使用批处理技术减少DrawCall数目。批处理技术原理是减少每帧需要的DrawCall数目,即每次调用DrawCall时尽可能的处理多个物体。
每一帧把可以进行批处理的模型网格进行合批,再把合并好的模型数据传递给GPU,然后使用同一种材质对其渲染。经过动态批处理的物体仍然可以移动,这是因为每帧Unity都会重新合并一次网格。
动态批处理条件限制:
(1)进行批处理的网格顶点属性规模要小于900,如果Shader有三个属性,那么顶点数目不能超过300个。
(2)多Pass的Shader会中断批处理。在前向渲染中,我们有时需要使用额外的Pass来为模型添加更多的光照效果,这样一来,模型就不会被动态批处理了。
在运行开始的阶段,把需要进行静态批处理的模型合并到一个新的网格结构中,这意味着模型不能再运行时被移动。往往需要占用更多的内存来存储合并后的网格结构。
无论是动态批处理还是静态批处理,都要求模型之间需要共享同一个材质。如果两个材质之间只是使用的纹理不同,可以把这些纹理合并到一张更大的纹理中,这张更大的纹理叫做图集(atlas)。
DrawCall:
DrawCall是CPU通过底层图像编程接口发出的渲染命令,GPU读取渲染命令执行渲染操作。
过多的DrawCall影响绘制的原因:
主要是每次绘制时,CPU通过底层图像编程接口发出渲染命令DrawCall,而每个DrawCall需要很多准备工作,检测渲染状态、提交渲染数据、提交渲染状态,而GPU本身可以很快处理完渲染任务。DrawCall过多,CPU负载过多,而GPU性能闲置。
渲染状态:
渲染状态定义场景中的网格是怎样被渲染出来的。例如使用哪个顶点着色器、哪个片元着色器、光源属性、材质等。如果没有更改渲染状态,所有的网格将使用同一种渲染状态。
CPU发送DrawCall需要完成的操作:
- CPU可以向GPU发送命令以将多个已知的变量统一地转换为渲染状态。此命令称为SetPass调用。SetPass调用告诉GPU用于渲染下一个网格的设置。仅当要渲染的下一个网格需要从前一个网格更改渲染状态时,才会发送SetPass调用。
- CPU将绘图调用发送到GPU。绘图调用指示GPU使用最近的SetPass调用中定义的设置呈现指定的网格。
- 在某些情况下,一个批次可能有多次Pass。对于批次中的每个Pass,CPU必须发送新的SetPass调用,然后必须再次发送DrawCall。
同时,GPU执行以下工作:
- GPU按照发送顺序处理来自CPU的任务。
- 如果当前任务是SetPass调用,则GPU更新渲染状态。
- 如果当前任务是DrawCall,则GPU渲染网格。这是分阶段发生的,由着色器代码的不同部分定义。渲染的这一部分很复杂,我们不会详细介绍它,但是我们理解一段称为顶点着色器的代码告诉GPU如何处理网格的顶点,然后是一段代码称为片段着色器告诉GPU如何绘制单个像素。
- 重复此过程,直到GPU处理完所有从CPU发送的任务为止。
(1)优化模型,尽可能的减少三角形的面数,移除不必要的硬边及纹理衔接,避免边界平滑和纹理分离。
边界平滑(smoothing splits,一个顶点可能会对应多个法线信息或切线信息,在Unity导入模型时,有一个Smoothing Angles(光滑组)的设置,当Smoothing Angles的值为0时,就没有共用的顶点,拆分出更多新的顶点,可以展示更多细节。当这个值越来越大,共用顶点越多,细节就更少一些。)
纹理分离(uv splits,一个顶点可能有多个纹理坐标。面与面之间使用的一些相同顶点,在不同面上,同一个顶点的纹理坐标可能并不相同 ,GPU会把这个顶点拆分成多个具有不同纹理坐标的顶点)。
(2)使用模型的LOD技术
LOD允许当对象逐渐远离摄像机时,减少模型上的面片数量,从而提高性能。
(3)使用遮挡剔除技术
消除在其他物体后面看不到的物体,也就不会渲染这个看不到的顶点,从而提高性能。注意:在移动平台,遮挡剔除开销太大,不建议使用。
(4)Camera.layerCullDistances
相机跟每一层的剔除距离。比如,在视野中有很多npc,可以把npc设置到npc层,并在代码中为npc层设置较小的layerCullDistances剔除距离,这样就可以只渲染npc层剔除距离内的npc,减少性能开销。
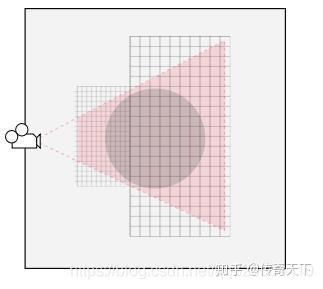
(5)注意摄像机的FOV(Field of View),影响可视物体的数量
(6)Camera视锥体越小越好,注意远裁减面的距离
考虑光照的影响可以每顶点,每像素的进行计算,光照计算可以通过多种方式进行优化:
- 实时光源越少越好,甚至不用实时光
- 利用离线烘焙,light mapping
- Spotlight(聚光灯)开销很大,少用
- 限制像素光的数量
- Culling Mask ,取消不需要进行光照计算的层
- 谨慎使用实时阴影
- 尽量用Hard Shadow
- 减少Shadow Distance
- 不用Shadow Castcade
补充:
Shadow Castcade
Shadow Castcade,就是远处的阴影用分辨率比较小的贴图,近处的阴影用分辨率比较大的贴图,提升了近处阴影的质量,但增加了性能开销。
?
Shadow Distance
超出此距离的物体(来自相机)不投射阴影,因为远处的对象不需要渲染到阴影贴图中。将阴影距离设置的尽可能低,可以提高渲染性能。
(1)控制绘制顺序,由于深度测试的存在,如果我们可以保证物体都是从前往后绘制,那么就可以很大程度上减少OverDraw,这是因为在后面绘制的物体由于无法通过深度测试,就不会在进行后面的渲染处理。
(2)在移动平台,渲染透明物体,Alpha混合性能比Alpha测试更好
(3)慎用实时光照
使用光照烘焙技术,把光照提前烘焙到一张光照纹理中(lightmap),在运行时根据纹理坐标得到光照结果。
(1)使用Shader的LOD技术
Shader的LOD技术可以控制使用的Shader等级。原理是只有Shader的LOD值小于某个设定值,这个Shader才会被使用。
在某些情况下,我们可能需要去掉一些使用复杂计算的Shader渲染。这时,我们可以使用Shader.maximumLOD或Shader.globalMaximumLOD来设置允许的最大LOD值。
(2)代码方面的优化
- 尽可能使用低精度的浮点值进行计算。
- 使用插值寄存器把数据从顶点着色器传递给下一个阶段时,应该使用尽可能少的插值变量。
- 尽量不要使用全屏的屏幕后处理效果,如果真的需要使用,尽量使用低精度计算,高精度计算可以使用查找表(LUT)或者转移到顶点着色器中进行处理。
- 把多个特效合并到一个shader中。
- 使用缩放思想,在高性能的平台,使用更高的分辨率,在低性能平台保证游戏正常运行即可,设置低一点的分辨率。
- 尽可能不要使用分支或循环语句。
- 尽可能避免使用类似sin、tan、pow、log等较为复杂的数学计算,请考虑使用查找纹理(lookup texture, LUT)作为复杂数学计算的替代方法。
节省内存带宽
(1)减少纹理大小,考虑目标分辨率和纹理坐标,长宽值最好是2的整数幂。这样很多优化策略才可以发挥最大效用。
(2)针对不同平台,采用压缩纹理来减少纹理大小,可以加快加载速度,减少内存占用,显著提高渲染性能。
在不同移动GPU平台下选择GPU支持的压缩纹理,就可以在不需要CPU解压的情况下直接被GPU采样,节省CPU内存和带宽,也可以节省存储的体积。如果目标平台不支持设置的压缩格式,纹理将解压为RGBA32或者RGB24,浪费CPU时间和内存。
(3)利用Mip Maps,始终为3D场景中使用的纹理启用Mip Maps。但此规则例外的是:UI元素或2D游戏中,不要使用。
Mip Maps(多级渐远纹理),根据摄像机远近不同而生成对应的八个贴图,运行会加载到内存中。远离相机时,使用较模糊的纹理。使用Mip maps需要使用33%以上的内存,但不使用它会导致巨大的性能损失。
优点:优化显存带宽,用来减少渲染。因为可以根据距离摄像机远近,选择适合的贴图来渲染。
利用Mip maps,对处理锯齿和闪烁的很有用。
(3)对于特定机型进行分辨率缩放,Screen.SetResolution,过高的屏幕分辨率是造成性能下降的原因之一,尤其对于很多低端手机。
根据不同的硬件平台,设置不同的配置,控制特效显示,分辨率大小设置等等。


