

Background
深度学习可以归结为一个优化问题,最小化目标函数 ;最优化的求解过程,首先求解目标函数的梯度
,然后将参数
向负梯度方向更新,
,
为学习率,表明梯度更新的步伐大小。最优化的过程依赖的算法称为优化器,可以看出深度学习优化器的两个核心是梯度与学习率,前者决定参数更新的方向后者决定参数更新程度。深度学习优化器之所以采用梯度是因为,对于高维的函数其更高阶导的计算复杂度大,应用到深度学习的优化中不实际。
深度学习的优化器有许多种类,学术界的研究也一直十分活跃,个人理解优化器可以分为两个大类。第一类是优化过程中,学习率 不受梯度
影响,全程不变或者按照一定的learning schedule随时间变化,这类包括最常见的SGD(随机梯度下降法),带Momentum的SGD,带Nesterov的SGD,这一类可以叫作SGD系列;另一类是优化过程中,学习率随着梯度
自适应的改变,并尽可能去消除给定的全局学习率的影响,这一类优化器有很多,常见的包括Adagrad Adadelta RMSprop Adam; 还有AdaMax Nadam Adamax NadamAMSgrad(ICLR 2018 best paper),以及最近比较火的Adabound,这一系列可以称为自适应学习率系列。
1.SGD系列
(1)SGD(Stochastic gradient descent)
更新公式:
SGD的梯度下降过程,类似于一个小球从山坡上滚下,它的前进方向只于当前山坡的最大倾斜方向一致(最大负梯度方向),每一个时刻的初速度为0
(2)SGDM Momentum 动量
更新公式:
SGD的梯度下降过程,类似于一个小球从山坡上滚下,它的前进方向由当前山坡的最大倾斜方向与之前的下降方向共同决定,小球具有初速度(动量),不只被梯度制约。SGDM克服了之前SGD易震荡的缺点,对比效果如下图:
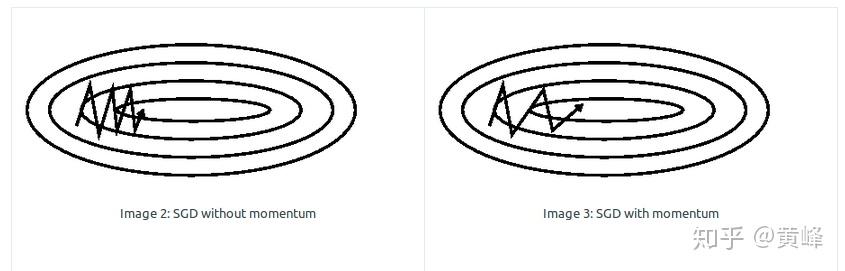
(3)Nesterov accelerated gradient
更新公式:
和带动量SGD十分接近,带Nesterov的小球,先按上一时刻初速度移动一个小位置,然后在新的位置它的前进方向由当前山坡的最大倾斜方向与之前的下降方向共同决定,见下图
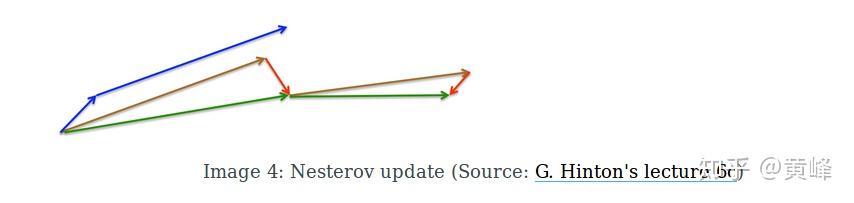
带Momentum的SGD,梯度下降方向由短蓝线(梯度更新 ) 长蓝线(上一时刻动量
)共同决定;带Nesterov的SGD,先在上一时刻动量方向跳跃一下(棕色线)更新位置(
),再在新的位置由当前梯度与动量决定下降方向
.
带Nesterov的SGD,nesterov项在梯度更新时做一个校正,避免前进太快,同时提高灵敏度。
2.自适应学习系列-常见系列
(1)Adagrad
通过以往的梯度自适应更新学习率,不同的参数 具有不同的学习率。Adagrad 对常出现的特征进行小幅度更新,不常出现的特征进行大幅度的更新,对比SGD对所有特征进行同样幅度的更新,十分适合处理稀疏数据。
具体的,SGD对每个参数 在每步
的更新公式为:
;
Adagrad对每个参数 在每步
的更新公式为:
,
是一个对角矩阵,它的每个元素是到步
的梯度平方和,
。
Adagrad的参数更新写成向量形式, 是平滑系数,防止零除。
。
可以看出,随着参数更新, 逐渐增大,
对应的学习率减少最终趋于0。
(2)Adadelta
Adadelta是对Adagrad的一个改进,它解决了Adagrad优化过程中学习率 单调减少问题。Adadelta不再对过去的梯度平方进行累加,而是改用指数平均的方法计算G_{t},Adagrad中的
替换为
,
,
对应
的均方误差根。
此时的Adadelta仍然依赖于全局的学习率 ,为消除全局学习率的影响,定义新的指数平均方法,
最终Adadelta更新规则为,
(3)RMSprop
RMSprop等价于Adadelta的第一种形式, 通常 设为0.9,
设为0.001
(4)Adam
在SGDM的基础上,引入自适应学习率
对应梯度
的一阶 二阶矩估计,是有偏估计,校正为无偏估计:
Adam 更新规则:
上述优化器算法都是很常见了的,
贴一个SGD SGDM Adgrad RMSprop Adam总结图:SGD SGDM Adgrad RMSprop Adam等优化器算法可以归结为一个在线凸优化问题[2],优化算法为:

不同的优化器对应不同的 函数,

(3)自适应学习系列-未名系列:AdaMax Nadam Adamax Nadam AMSgrad(ICLR 2018 best paper),以及最近比较火的Adabound
AdaMax
Adam变体,Adam中用 norm度量梯度大小,
进一步推广为 norm形式,
,
Adamax便是用无穷范数 度量梯度大小,用于收敛到更稳定的状态
AdaMax update rule: 被
代替,
好的默认设置:
Nadam(Nesterov-accelerated Adaptive Moment Estimation)
RMSprop与momentum的组合,
,
Adam中的 换为
AMSGrad
ICLR2018提出的,文章指出Adam等优化器由于指数平均的方法使得对梯度的记忆是短期记忆,导致不能优化到全局最优点,泛化性能弱于SGD。AMSgrad中, 的更新方式改变为
无偏差修正估计的完整AMSGRAD更新如下:
Adabound
对学习率进行裁剪,对比AMSgrad效果更优

参考:


