

前面已经介绍过System R的基于动态规划的bottom-up优化器实现,参考Access Path Selection in a Relational Database Management System。本文介绍经典的top-down类型的优化器实现——Volcano Optimizer Generator。Volcano Optimizer Generator很多设计思路脱胎于EXODUS,同时解决了很多EXODUS的不足,比如区分了逻辑表达式和物理表达式,支持了可扩展的物理properties。除了提供更强大的功能支持之外,volcano的搜索性能要高得多。
Abstract
volcano项目可以同时为数据库提供丰富的新功能扩展以及高性能 。volcano不仅仅提供了执行器模型,同时提供了一个优化器生成器(optimizer generator)。优化器生成器会将定义的数据模型、逻辑代数、物理代数和优化规则转换为优化器源代码。与更早的的 EXODUS 优化器生成器原型相比,volcano的搜索引擎的可扩展性更强,功能更强大;并且为代价模型和物理属性(physical properties)提供了有效的支持。除了提供更强大的功能支持之外,volcano的搜索性能要高得多,因为它将动态编程(当前只用于SPJ优化)与goal-directed search和branch-and-bound裁剪结合。与其他RBO系统相比,它提供了完全的数据模型独立性和更自然的可扩展性。
虽然可扩展性是当前许多数据库研究项目和系统原型的重要目标和要求,但不能为此牺牲性能。早期使用EXODUS 优化器生成器的经验已经证明了优化器生成器范式的可行性和有效性。但构建高效的、生产质量的优化器却很困难。因此,我们设计了一个新的优化器生成器,该优化器生成器对 EXODUS 原型做了一些重要的改进。
- 这个新的优化器生成器必须既可以在带有现有查询执行软件的 Volcano 项目中使用,也可以作为独立工具在其他项目中使用
- 新系统必须在优化时间和搜索的内存消耗方面更加高效
- 新系统必须为排序顺序和压缩状态等physical properties提供有效、高效和可扩展的支持
- 新系统必须允许使用启发式方法和数据模型语义来指导搜索并裁剪搜索空间中无用的部分
- 新系统必须支持灵活的代价模型,允许为不完全指定的查询生成动态计划
在本文中,我们描述了 Volcano Optimizer Generator,它将很快满足上述所有要求。
优化器生成器的设计范例如下图1所示:
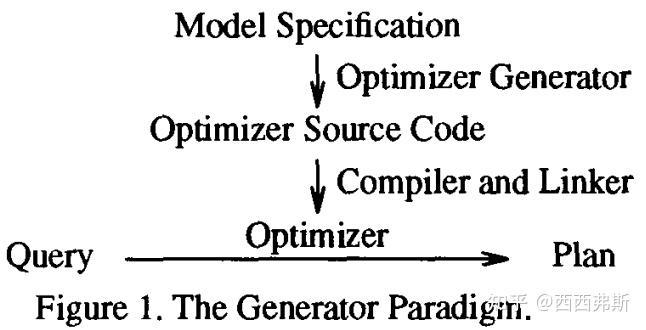
在构建DBMS时,model specification被转换为优化器源代码,该代码被编译并与其他 DBMS 软件(例如查询执行引擎)链接。其中一些软件是由优化器实现者编写的,例如代价函数。将数据模型描述(data model description )转换为优化器的源代码后,生成的代码将被编译并与作为 Volcano 优化软件一部分的搜索引擎链接。当 DBMS 运行并输入查询时,查询将传递给优化器,优化器会为其生成优化的执行计划。
系统中体现了五个基本设计决策,这些决策有助于使用 Volcano 优化器生成器设计和实现具有可扩展性和高搜索效率的优化器。
- 查询处理基于关系代数。代数算子消耗一个或一批tuples,并生成下一个算子的输入。算子集和算法集是不同的,为算子选择最高效的实现算法是查询优化的中心任务之一。Volcano 优化器生成器使用两种类型的代数(称为逻辑代数和物理代数),生成将逻辑代数表达式(查询)映射到物理代数表达式(由算法组成的查询评估计划)的优化器。为此优化器需要支持使用transformations将逻辑代数表达式变形为等价形式,并支持逻辑算子到物理实现算法的基于代价的映射。
- 规则已被确定为一个通用概念,可以以简洁和模块化的方式指定有关模式的知识,并且可以使用模式和规则轻松地表达查询优化中等价变换所需的代数定律知识。大多数可扩展查询优化系统都使用规则,包括 Volcano 优化器生成器。对独立规则的关注确保了模块化的实现。在我们的设计中,规则是相互独立翻译的,并且仅由搜索引擎在优化查询时组合。考虑到查询优化是任何数据库系统中概念上最复杂的组件之一,模块化本身对于优化器的初始构建和维护都是一个优势。
- 查询优化器可以做出的将查询映射到最佳等价查询评估计划的选择,这些等价查询评估计划以等价代数表达式的形式作为volcano优化器生成器的输入,优化器生成器的搜索引擎以合适的方式应用它们。然而,对于希望对搜索进行控制的数据库实现者,例如希望指定搜索和裁剪的启发式规则的数据库实现者,将有可选的工具来实现这一点。
- 规则是解释执行还是编译执行。一般来说,解释可以变得更加灵活(特别是可以在运行时增强规则集),而编译的规则集通常执行得更快。由于查询优化非常消耗 CPU 资源,因此我们决定使用类似于 EXODUS 优化器生成器的规则编译。此外,我们认为扩展查询处理系统及其优化器是如此复杂和耗时,以至于永远无法快速完成,这使得解释器的最有力的论据变得毫无意义。为了通过编译的规则集获得额外的灵活性,参数化规则及其条件可能是有用的,例如,控制搜索的彻底性,以及观察和利用规则应用的重复序列。一般来说,搜索引擎的灵活性问题和解释与编译之间的选择是正交的。
- Volcano 优化器生成器生成的优化器使用的搜索引擎基于动态编程实现。
Volcano 优化器生成器的一个主要设计目标是最小化有关要实现的数据模型的假设,因此优化器生成器仅提供一个框架,优化器实现者可以将数据模型特定的操作和功能集成到其中。在本节中,我们讨论优化器实现者在实现新的数据库查询优化器时定义的组件。用户查询是生成的优化器的输入,物理执行计划是生成的优化器的输出,如图1所示。本节讨论的所有其他组件均由优化器实现者在优化器生成之前以等价规则和支持函数的形式指定,在优化器生成期间进行编译和链接,然后由生成的优化器在优化查询时使用。
- 用户查询经过parser后生成一个逻辑算子树,作为生成的优化器的输入,生成的优化器将逻辑执行计划优化为物理执行计划。逻辑算子集在模型规范中声明,并在生成期间编译到优化器中,算子的输入数量不是固定的。优化器的输出是一个物理执行计划。
- 优化包括将逻辑代数表达式映射到最佳等价物理代数表达式。换句话说,生成的优化器会对算子重新排序并选择实现算法。使用transformation规则指定逻辑表达式等价的代数规则。使用implementation规则实现逻辑算子到物理算法的映射。规则语言能够允许复杂的映射存在是非常重要的。例如,应在允许单个过程中实现join后紧跟着进行投影(不去重),从而将多个逻辑算子映射到单个物理算子。除了算子和实现算法的简单模式匹配之外,还可以使用这两种规则指定附加条件。这是通过将条件代码附加到规则来完成的,该规则将在模式匹配成功后调用。
- 表达式的结果使用properties来描述,类似于 EXODUS 优化器生成器和 Starburst 优化器中的properties概念。逻辑properties可以从逻辑代数表达式导出,包括schema、预期size等,而物理properties取决于实现算法,例如排序顺序、分区等。优化many-sorted代数时,逻辑properties还包括中间结果的类型(或排序),可以通过规则的条件代码进行检查,以确保规则仅应用于正确类型的表达式。逻辑properties附加到等价类(等效逻辑表达式和计划的集合),而物理properties附加到特定计划和算法选择。
- 每个中间结果的物理属性集都汇总在物理属性向量中,该向量由优化器实现者定义,并由 Volcano 优化器生成器及其搜索引擎视为抽象数据类型。换句话说,物理属性的类型和语义可以由优化器实现者设计。物理代数中有一些算子与逻辑代数中的任何算子都不对应,例如排序和解压缩。这些算子的目的不是执行任何逻辑数据操作,而是在其输出中强制执行后续查询处理算法所需的物理属性。这些算子被称为enforcers。一个enforcer可能保证了两个属性,或者保证一个属性但破坏另一个属性。
- 每个优化目标(和子目标)都是一个pair(逻辑表达式,物理属性向量)。为了决定是否可以使用算法或执行器来执行逻辑表达式的根节点,生成的优化器匹配实现规则,执行与规则关联的条件代码,然后调用applicability function来确定算法或执行器是否可以传递具有满足物理属性向量的物理属性的逻辑表达式。applicability function还确定算法输入必须满足的物理属性向量。例如,当优化其结果应根据join属性进行排序的join表达式时,hybrid hash join算法不能满足物理属性而sort merge-join能够满足有序属性。或者通过引入一个sort enforcer来保证有序性,经过排序后,hybrid hash join就能够使用了。还有一项规定可确保算法不会冗余地限定,例如,merge-join的输出不得被视为本示例中排序的输入。
- 在优化器决定使用算法或enforcer后,它会调用算法的Cost函数来估计其Cost。Cost 是优化器生成器的抽象数据类型;因此,优化器实现者可以选择Cost为数字(例如,估计的运行时间)、record(例如,估计的 CPU 时间和 I/O 计数)或任何其他类型。Cost计算和比较是通过调用与抽象数据类型“Cost”相关联的函数来执行的。
- 对于每个逻辑和物理代数表达式,使用property functions导出逻辑和物理属性。每个逻辑算子、算法和enforcer都必须有一个property functions。在执行任何优化之前,逻辑属性是由与逻辑算子关联的property functions基于逻辑表达式确定的。例如,可以独立于许多等效代数表达式中的哪一个创建中间结果来确定中间结果的模式。逻辑属性函数还封装了selectivity estimation。另一方面,诸如排序顺序之类的物理属性只能在选择执行计划后才能确定。作为众多一致性检查之一,生成的优化器验证所选计划的物理属性确实满足作为优化目标的一部分给出的物理属性向量。
综上,优化器实现者提供了:
- (1) 一组逻辑算子
- (2) 代数transformation规则,可能带有条件代码
- (3) 一组算法和enforcers
- (4) implementation规则,可能带有条件代码
- (5) 具有基本算数计算和比较功能的ADT“Cost”
- (6) ADT“logical properties”
- (7) ADT“physical property vector”,包括比较函数
- (8) 每个算法和enforcer的applicability function
- (9) 每个算法和enforcer的cost function
- (10) 每个算子、算法和enforcer的property function
这些都实现的话看起来可能是很多代码,然而,构建带有或不带有优化器生成器的数据库查询优化器都需要实现所有这些功能。考虑到查询优化器通常是数据库管理系统中最复杂的模块之一,并且优化器生成器为这些必要的优化器组件规定了干净的模块化,因此使用 Volcano 优化器生成器构建新的数据库查询优化器的工作量应该大大减少。使用 Volcano 优化器生成器的优化器实现者不需要设计和实现新的搜索算法。
由于数据库查询优化的一般范例是:先创建等价查询评估计划,然后在许多可能的计划中进行选择。因此搜索引擎及其算法是任何查询优化器的核心组件。Volcano 优化器生成器提供了一个可在所有创建的优化器中使用的搜索引擎,而不是强制每个数据库和优化器实现者实现全新的搜索引擎和算法。该搜索引擎自动与从数据模型描述生成的模式匹配和规则应用代码链接。
动态编程以前已用于数据库查询优化,特别是在 System R 优化器和 Starburst cost-based的优化器中,但仅适用于SPJ查询。Volcano 优化器生成器设计的搜索策略(search strategy)将动态编程从关系连接优化扩展到一般代数查询和请求优化,并将其与自上而下、面向目标的代数控制策略相结合,其中可能的计划数量超出了预计算的实际限制。我们的动态编程方法仅为那些被视为较大子查询(以及整个查询)一部分的部分查询导出等价表达式和计划,并非所有等价的表达式和计划都是feasible或满足interesting order。
虽然 EXODUS 优化器生成器以及 System R 和 Starburst 关系系统的搜索引擎使用前向链接(forward chaining),Volcano 搜索算法使用向后链接(backward chaining),因为它只探索那些真正参与更大表达式的子查询和计划。我们称我们的搜索算法为directed dynamic programming。动态编程被使用 Volcano 优化器生成器创建的优化器使用,通过保留大量部分优化结果并在以后的优化决策中使用这些早期结果。目前,这组部分优化结果会针对每个正在优化的查询重新初始化。换句话说,早期的部分优化结果仅仅会被当前查询使用。部分优化结果(比如某个查询结构的优化结果)的跨语句使用在未来工作规划中。
代数变换系统(Algebraic transformation systems)总是包含以多种不同方式导出相同表达式的可能性。为了通过在优化期间防止冗余优化工作,需要能够检测出相同逻辑表达式和计划。表达式和计划被捕获在表达式和等价类的哈希表中。等价类表示两个集合,一个是等价逻辑集合,另一个是等价物理表达式(计划)。逻辑代数表达式用于有效且完整地探索搜索空间,计划用于快速选择满足物理属性要求的合适输入计划。对于等价类已优化的每个物理属性组合(例如,未排序、按 A 排序、按 B 排序),将保留找到的最佳计划。
图 2 显示了 Volcano 优化器生成器使用的搜索算法的概要。

FindBestPlan过程的输入为用户要优化的查询的逻辑表达式、用户请求的物理属性(例如,SQL 的 ORDER BY 子句中的排序顺序)以及代价限制。对于用户查询来说,limit通常是无限的。但是允许用户自己配置limit限制以“捕获”不合理的查询,例如,由于缺少连接谓词而使用笛卡尔积的查询。FindBestPlan 过程分为两部分:
- 首先,如果可以在哈希表中找到满足物理属性向量的表达式的计划,则根据找到的计划是否满足给定的成本限制,返回该plan及其cost或失败指示。
- 如果在哈希表中找不到该表达式,或者如果该表达式之前已被优化但不符合当前所需的物理属性,则开始实际优化。
优化器可以随时探索三组可能的“移动”:
- 首先,可以使用transformation规则来实现表达式变形。
- 其次,可能有一些算法可以提供具有所需物理属性的逻辑表达式,例如,用于未排序输出的hybrid hash join和用于在连接属性上排序的连接输出的merge join。
- 第三,enforcer可能有助于允许额外的算法选择,例如,即使最终输出要排序,提前使用排序算子作为enforcer使得满足排序属性也允许使用hybrid hash join。
在生成并评估了所有可能的移动之后,将采取最有希望的移动。目前仅实现了exhaustive search,所有可能的move都会被探索。优化器可以选择是探索所有move还是通过启发式规则只探索部分move。
Cost限制用于改进使用branch-and-bound pruning的搜索算法。一旦知道逻辑表达式(用户查询或其某些部分)和物理属性向量的完整计划,则没有其他计划或具有较高成本的部分计划可以成为最佳查询评估计划的一部分。因此,即使优化器使用穷举搜索,快速找到相对好的计划也很重要。此外,cost限制被传递到子表达式的优化中,并且严格的上限也加速了它们的优化。
1)如果要进行的移动是transformation,则使用 FindBestPlan 形成新的表达式并对其进行优化。为了检测两个(或更多)规则彼此相反的情况,当前表达式和物理属性向量被标记为“in progress”。如果新形成的表达式在哈希表中并被标记为“in progress”,则它将被忽略,因为其最佳计划在完成时才考虑。
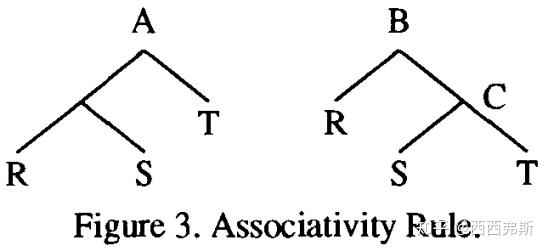
通常transformation会生成一个新的等价类,考虑图 3 中的关联性规则(associativity rule)。以 A 和 B 为根的表达式是等价的,因此属于同一类。但是,表达式 C 不等于左侧表达式中的任何表达式,需要一个新的等价类。在这种情况下,由于表达式 B的cost分析和优化的需要, 需要创建并优化一个新的等价类。
本节将详细比较 EXODUS 和 Volcano 优化器生成器。生成器的概念非常成功,因为输入数据(数据模型规范)可以转换为机器代码;然而,EXODUS 优化器生成器的搜索引擎远非最佳。Volcano 优化器生成器解决了EXODUS 优化器生成器的三个问题,并包含 EXODUS 优化器生成器中没有的新功能。
EXODUS 和 Volcano 优化器生成器的功能和可扩展性存在几个重要差异。
- 首先,Volcano区分了逻辑表达式和物理表达式。
- 其次,EXODUS 中对物理属性的处理相当随意。换句话说,EXODUS 中完全不具备指定所需物理属性并让这些属性与逻辑表达式一起驱动优化过程的能力,但这种能力对 Volcano 优化器生成器搜索引擎的效率做出了重大贡献。
- 第三,Volcano算法是自上而下驱动的; 仅在有保证的情况下才优化子表达式。在 EXODUS 中,transformation之后总是立即进行算法选择和成本分析。
- 第四,Volcano 中的cost定义比 EXODUS 优化器生成器中的更通用。在 Volcano 中,成本是一种抽象数据类型,所有计算和比较都是通过调用优化器实现者提供的函数来执行的。
- 最后,我们相信 Volcano 优化器生成器比 EXODUS 原型更具可扩展性,特别是在搜索策略方面。保存逻辑表达式和物理计划的哈希表以及对该哈希表的操作非常通用,并且支持多种搜索策略。
在本节中,我们通过实验比较 EXODUS 和 Volcano 搜索引擎中内置机制的效率和有效性。用于此比较的示例是一个相当小的“数据模型”,仅由关系选择和连接算子组成;然而,正如我们将看到的,即使是这个小数据模型和查询语言也足以证明 Volcano 优化器生成器的搜索策略优于为早期 EXODUS 原型设计的搜索策略。
测试关系包含 1,200 至 7,200 条 100 字节的记录。cost函数包括 I/O 和 CPU 成本。图 4 显示了平均优化工作量,并且为了显示优化器输出的质量,还显示了针对具有 1 到 7 个二元连接(即 2 到 8 个输入关系以及与输入关系一样多的选择)的查询生成的计划的估计执行时间。实线表示 Sun SparcStation-1 上的优化时间,速度约为 12MIPS。虚线表示估计的计划执行时间。
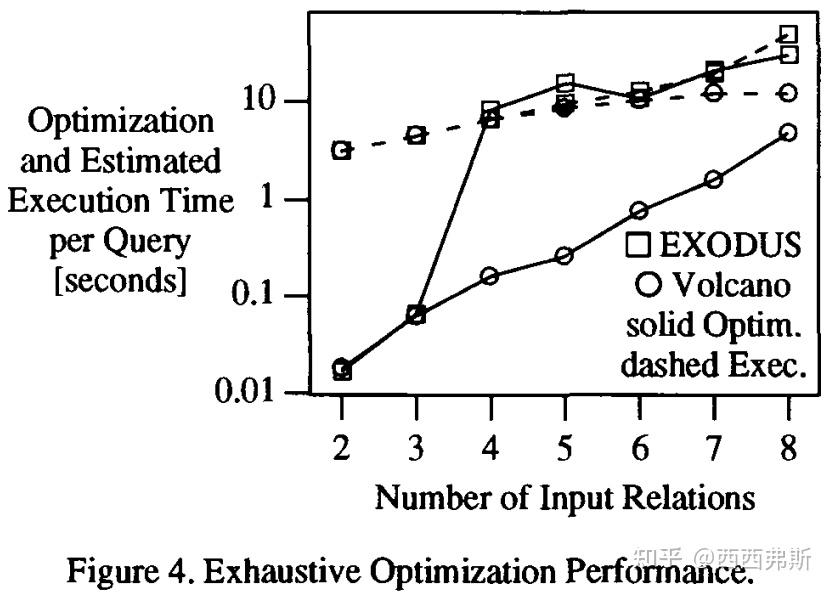
搜索时间反映了 Volcano 更高效的搜索策略,从两条实线之间的较大距离可见。对于 EXODUS 生成的优化器,搜索工作量在关系数量从3增加到4时急剧增加,因为此时重新分析已成为 EXODUS 中查询优化工作的重要组成部分。Volcano 的优化成本呈指数增长,几乎呈直线,这恰好反映了等价逻辑代数表达式数量的增长。对于更复杂的查询,EXODUS 和 Volcano 的优化时间相差大约一个数量级。
对于中等复杂的查询(最多 4 个输入关系),计划质量大体相同,然而,对于更复杂的查询,EXODUS 优化计划的成本要高得多,因为 EXODUS 生成的优化器及其搜索引擎不会系统地探索和利用physical properties和interesting orderings。
总而言之,Volcano 优化器生成器不仅可扩展性更强,而且比早期的 EXODUS 原型更加高效和有效。
Starburst 可扩展关系数据库管理系统的查询优化器由两个具有嵌套范围的基于规则的子系统组成。这两个子系统通过一个公共数据结构连接,该数据结构表示整个查询,称为查询图模型(QGM)。
- 第一个子系统称为查询重写(query rewrite)。它合并嵌套子查询并捆绑选择和连接谓词,以便在第二个基于cost的优化器中进行优化。查询重写阶段的优化完全基于启发式规则,对cost不敏感。
- 第二个子系统称为cost-based optimizer,负责优化SPJ查询。他执行基于规则的扩展,将SPJ查询从关系演算优化为访问计划,并通过估计的执行cost比较结果计划。基于成本的优化器在某些结构边界内执行详尽的搜索。例如,可以选择将搜索空间限制为只包含左深树,包含所有bushy-tree,或者只包含部分bushy-tree。
对于中等复杂的join查询,Starburst 基于成本的优化器的穷举搜索速度非常快,因为它使用了动态编程。此外,CBO会考虑排序顺序等物理属性,并创建有效的访问计划,其中包括“粘合”算子以强制执行物理属性。
Starburst 的可扩展查询优化方法存在两个基本问题:
- 首先,CBO的设计侧重于基于grammar-like规则的连接表达式的逐步扩展。问题在于,现有规则集如何与additional operators和扩展规则交互。Volcano 的代数方法看起来更自然、更容易理解。
- 其次,为了避免与向CBO添加新算子相关的问题,Starburst会在查询重写级别集成新算子。然而,查询重写级别上的查询优化是启发式的;换句话说,它不包括成本估算。我们相信,所有代数等价性和变换都以单一语言指定并由单一优化器组件执行的单级方法更有利于数据库查询代数及其优化的未来研究和探索。火山优化器生成器将允许通过适当的排名和“移动”选择来进行启发式转换:它让数据库实现者选择何时以及如何使用启发式与成本敏感的优化,而不是像 Starburst 设计中那样先验地做出这种选择。
为了同时提供丰富的功能以及优秀的性能,Volcano 项目提供了高效、可扩展的查询和请求处理工具。不建议将关系查询处理重新引入下一代数据库系统,相反,我们致力于开发一种独立于任何数据模型的新型查询处理引擎。基本假设是:高级查询和请求语言现在并在未来将继续基于集合、其他bulk 类型、谓词和算子。因此,消费和产生item序列或集合的算子是下一代查询和请求处理系统的基本构建块。换句话说,我们假设某些集合代数(algebra of sets)是查询处理的基础,并且我们的研究试图支持任何集合代数,包括heterogeneous collections和many-sorted algebras。幸运的是,代数和代数等价规则是数据库查询优化的非常合适的基础。此外,集合和在它们之间传递数据的算子也是数据库查询处理的并行算法的基础。因此,我们对可扩展数据库系统中查询处理的基本假设与高性能并行处理兼容。
Volcano 研究提供的工具之一是一个新的优化器生成器,其设计和实现是为了进一步探索搜索引擎的可扩展性、搜索算法、有效性(即生成计划的质量)、启发式规则以及搜索引擎的时间和空间效率。
- 可扩展性(Extensibility)的实现是通过从数据模型specifications生成optimizer源码,并且将cost以及logical/physical properties封装到抽象数据类型中实现的。
- 有效性(Effectiveness)是通过允许穷举搜索来实现的,由优化器实现者自行决定是否进行裁剪。
- 高搜索效率(Efficiency)通过将动态规划与基于物理属性、分支定界修剪和启发式指导的定向搜索相结合,形成一种新的搜索算法(directed dynamic programming)实现。
除了将基于动态规划的穷举搜索的高效实现与 EXODUS 优化器生成器的通用性和更自然的单级代数变换方法相结合,Volcano 优化器生成器具有许多新功能,这些功能增强了其作为软件开发和研究工具的价值,超越了所有早期的可扩展查询优化工作。
- 首先,对于启发式transformations vs cost-sensitive优化,何时以及如何使用的选择并没有明确的规定。在 EXODUS 中,cost分析总是在transformation之后进行;在 Starburst 中,设置两个级别,一个级别只能执行启发式优化,而另一级别则执行cost-sensitive的穷举搜索。因此,Volcano 优化器生成器消除了早期可扩展查询优化器设计对搜索策略施加的限制。
- 其次,使用 Volcano 优化器生成器生成的优化器非常有效地使用物理属性(physical properties)来指导搜索。不是首先优化表达式,然后将"glue"算子及其成本添加到计划中(Starburst的做法),Volcano 优化器生成器的搜索算法立即考虑要强制执行哪些物理属性以及可以由哪个enforcer算法强制执行,并从用于branch-and-bound pruning的边界中减去enforcer算法的成本。因此,Volcano 优化器生成器有望在搜索和裁剪方面比关系型 Starburst 优化器更加高效。
- 第三,对于可以受益于物理属性的多个替代组合的二元(三元等)运算,可以多次优化子表达式。例如,只要两个输入以相同的方式排序,基于merge join的交集算法就可以利用任何排序顺序。
- 第四,等价类的内部结构足充分模块化和可扩展,以支持替代搜索策略,远远超出了规则条件代码的参数化,这在 Starburst 和 EXODUS 中可以找到大致相似的程度。我们正在探索关于搜索策略的几个方向,比如:1)preoptimized subplans;2)learning of transformation sequences;3)一种替代的、甚至更加参数化的搜索算法,可以“切换到不同的现有算法;4)并行搜索(在共享内存机器上)。
- 最后,逻辑代数和物理代数的consistent separation使得任一级别的specification和modifications对于数据库和优化器实现者来说都特别容易,并且使搜索引擎非常高效。Volcano 设计利用了搜索引擎中的这种分离,这使得扩展优化器实现者提供的代码更容易编写、理解和修改。


