

1. 关于 LTO 、-flto 、ThinLTO
- LTO(Link Time Optimization)链接时优化是链接期间的程序优化,多个中间文件通过链接器合并在一起,并将它们组合为一个程序,缩减代码体积,因此链接时优化是对整个程序的分析和跨模块的优化。IPO(IPA)的说明介绍可参考:编译优化之 - 过程间优化(IPA/IPO)入门
link time时需要为GP alias计算大小,是否超过16bit,以决定用什么东西。该计算在linker中做而不是compiler来做。 - flto是使用lto的主要方法,是一个优化选项,禁用lto使用-fno-lto。flto主要做的操作有inline、ipa和alias分析等。
- ThinLTO是一种可扩展和增量式的新型LTO,与LTO相比,表现甚至更好。要使用ThinLTO,只需添加-flto=thin选项即可进行编译和链接。第一阶段类似于传统LTO的步骤,在进行一些早期优化(主要是为了减小大小)之后,调用前端将每个输入源文件转换为包含IR的中间文件。只是使用ThinLTO,每个文件中都包含一个附加的摘要部分。ThinLTO overview如下:
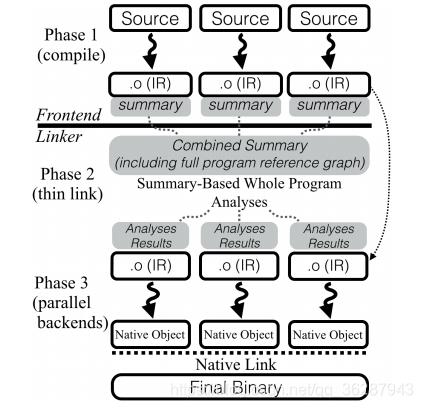
2. LLVM或AOCC中flto
LLVM中lto work在IR(Intermediate representation)上,我们常用的选项其实代表,指将分散的目标文件的所有LLVM IR组合到一个大的LLVM模块中,然后对其进行整体分析优化并生成,该选项仅并行执行前端的语义分析,优化和生成在单线程完成。则是把模块分开,根据需要才从其他模块导入功能,并且除全局分析外均采用并行的方式进行优化和的生成。因此使用比编译链接的速度大大加快,而且对于部分性能更好。
2.1 Linkers
ThinLTO当前在LLVM编译器中实现,其思想是主要是指导inline优化。它支持以下三种链接器:
- :使用前需要先安装插件,然后就可以使用。安装请见(The LLVM gold plugin)。
- :从Xcode 8开始。
- :来自于llvm项目,运行速度更快,特别是在众核处理器上。默认支持LTO,lld读取进行编译优化并输出文件。详细请见(The LLVM Linker — lld)。LLVM中关于lld的详细说明介绍请见知乎大佬的:LLVM中的lld程序流程分析 这篇文章。
基本用法:
- 备注:在或更高版本中已不再使用作为链接器,而是使用lld作为default linker。在或更高版本中使用指定链接器。
3. GCC和ICC中flto
3.1 GCC中用法
GCC-4.6.0中开始支持LTO框架,主要分为:Partitioned LTO和Non-Partitioned LTO
分区的LTO(Partitioned LTO)整体步骤为:
- LGEN:生成摘要信息;生成转换单元信息
- WPA(Whole Program Analysis):读取除函数体外的call graph信息;每个函数的摘要信息
- LTRANS:局部转换
处理顺序为:
- gcc executes LGEN
- Subsequent process of lto1 executes WPA
- Subsequent independent processes of lto1 execute LTRANS
不分区的LTO(Non-Partitioned LTO)整体步骤为:
- LGEN:生成转换单元信息
- IPA(InterProcedural Analysis) :读取call graph和函数体内容;进行分析和转换
处理顺序为:
- gcc executes LGEN
- Subsequent process of lto1 executes IPA
以上内容摘自于:https://www.cse.iitb.ac.in/grc/slides/pldi14tut-gcc/5-gcc-pldi14-lto-mechanism.pdf,是以GCC-4.7.2版本源码进行的分析说明。
GCC中使用编译代码时,它将生成,并将其写到目标文件的(部分的数据结构和枚举代码在 lto-streamer.h中),将目标文件链接在一起时,将从这些ELF中读取所有功能体,并将其实例化(链接期间,所有对象模块放在一起并调用lto1)。当前,大多数基于ELF的系统以及,和系统都启用了LTO支持。
从源码时使用编译,所有的在中管理,它包含两个:
- pass_ipa_lto_gimple_out:该pass执行函数体lto_output在lto-streamer-out.c文件中。它遍历调用图,对每个可达的声明,类型和函数进行编码。
- pass_ipa_lto_finish_out:该pass执行函数体produce_asm_for_decls在lto-streamer-out.c文件中。它获取上一步中的结果并将其编码在相应的ELF文件节中。
GCC中基本用法:
GCC中如果你想知道你的代码从前端开始的编译过程中做了哪些pass,可使用、或者打印出来,如下:

由上图可看出,源码经过前端处理之后在中端需要经过很多处理,你可以结合gdb看到每一个处理过程的转换信息。
对于最简单的 printf(“hello world”),在GCC中没有选项的情况下得到的汇编码如下:
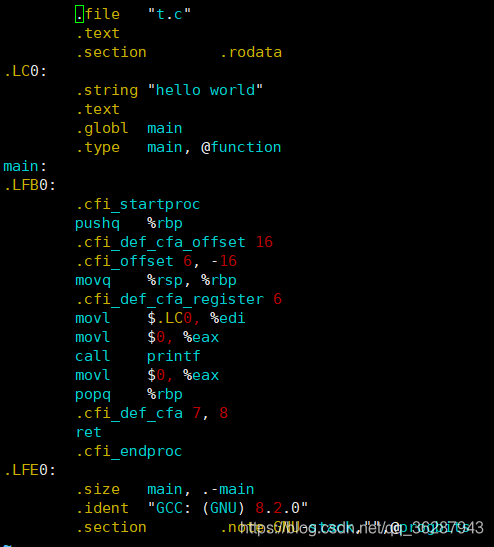
使用之后的大致输出信息如下:

由此看出:输出不包含目标代码,而仅包含信息。
关于优化的具体信息可通过打印出来:
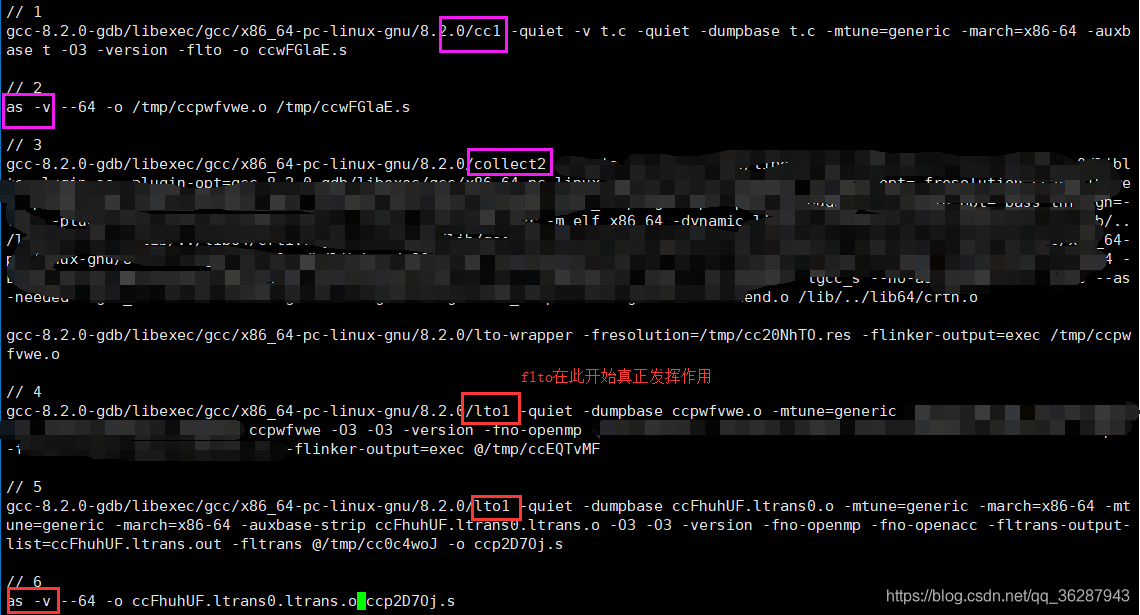
在以上标注的6个步骤中,真正开始起作用是从第4步开始,位置。
3.2 ICC中用法
ICC中提供了使用选项的链接时优化,以实现GCC兼容性。ICC中的链接时优化是在IPO中选取启用的。
ICC中基本用法:
4. 注意点
- LTO生成的文件并不是真正的,而是一个携带优化信息的中间文件,这些文件通过整理分析之后合并成最终可执行文件。
- 使用LTO会导致编译链接速度变慢,占用更大的内存空间。
- 一些选项不支持和一起使用,例如:等。甚至配合某些选项使用时一些benchmark编不过。


