

- 🍨 本文为🔗365天深度学习训练营?中的学习记录博客
- 🍦? 参考文章:365天深度学习训练营-第11周:优化器对比实验(训练营内部成员可读)
- 🍖 原作者:K同学啊|接辅导、项目定制
目录
?

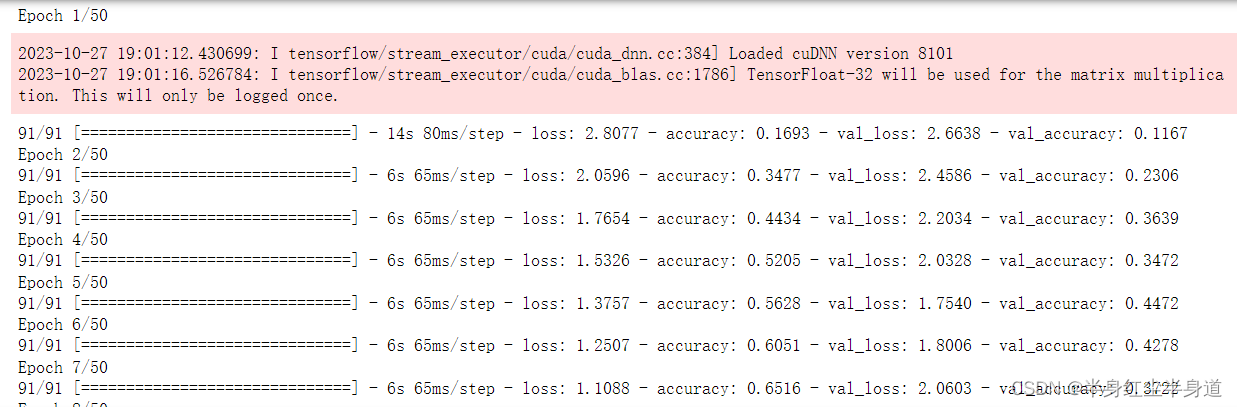
Adam优化器:
 ?
?
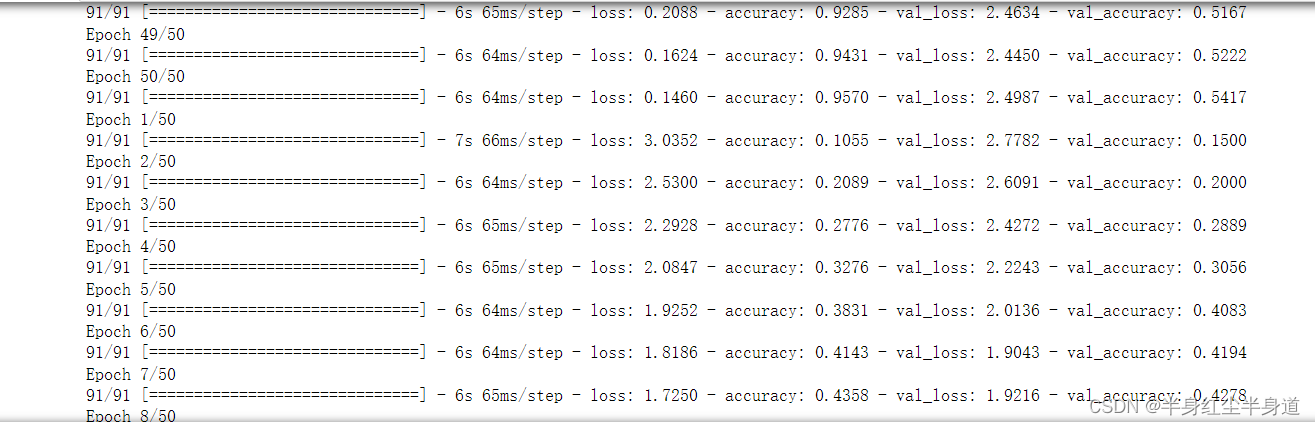
?SGD优化器:
?
?![]()
Adam优化器(Adaptive Moment Estimation)和随机梯度下降(SGD)是两种用于训练神经网络的常见优化算法,它们各自具有一些优点和缺点。
优点:
-
自适应学习率: Adam根据每个参数的历史梯度信息来自动调整学习率。这有助于在训练初期更快地收敛,同时在接近最优解时减小学习率,以更稳定地收敛到最小值。
-
动量项: Adam引入了动量项,使得在参数更新中考虑了先前梯度的平均。这有助于克服SGD中的梯度噪声,特别是在存在大量噪声的数据中。
-
适用于不同问题: Adam通常对各种深度学习问题表现良好,且无需太多超参数调整。
缺点:
-
内存消耗: Adam需要存储每个参数的历史梯度信息,这可能导致内存消耗较大。
-
不稳定性: 在某些情况下,Adam可能会在训练后期不稳定,导致模型性能下降。这通常需要更小的学习率或其他调整来解决。
Adam利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。堆内存的需求比较小,也适用于大数据集和更高维空间的模型。
优点:
-
计算开销小: SGD的计算成本通常较低,因为它只使用小批次的数据进行梯度计算。
-
较少内存消耗: 与Adam相比,SGD需要较少的内存,因为它不需要存储历史梯度信息。
-
噪声有助于逃离局部极小值: SGD引入了梯度噪声,这有助于使模型跳出局部极小值并探索更广泛的参数空间。
缺点:
-
需要调整学习率: SGD通常需要手动调整学习率,并且学习率的选择可能会影响训练的成功与否。
-
训练时间较长: 由于SGD在更新参数时通常需要更多的迭代次数,因此它可能需要更长的时间来收敛。
-
不适用于某些问题: 对于一些问题,特别是在存在大量噪声的数据中,SGD可能无法有效地收敛。
SGD是一种随机梯度下降优化器,SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。
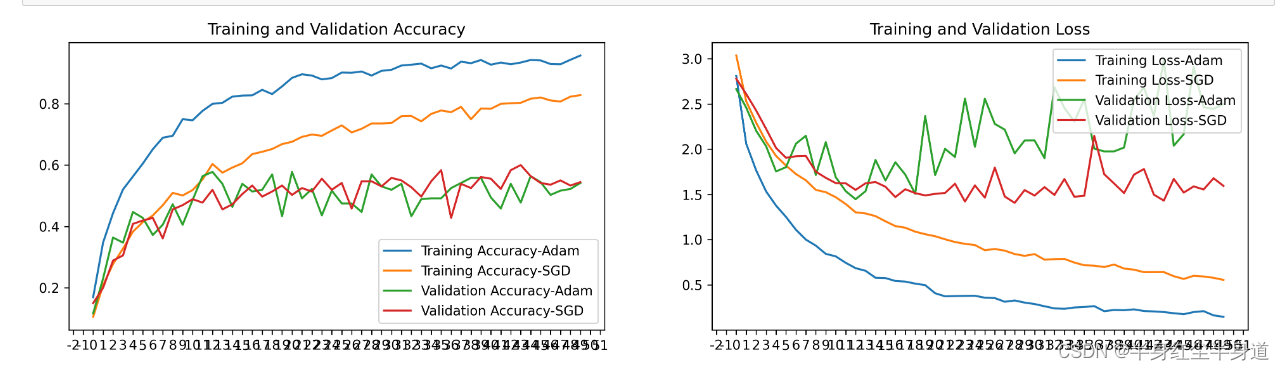
Adam优化器和SGD优化器各自有各自的优点,在图像噪声比较多的时候更适合使用Adam优化器,同样,当损失出现陷入局部最小的问题时当然还是SGD优化器更能避免这个问题。


